AMG性能优化相关文章
版权声明:
除非注明,本博文章均为原创,转载请以链接形式标明本文地址。
Create 2023-03-31
Update 2023-10-11
Update 2024-06-04
Update 2024-06-11
性能优化是一个非常广泛的概念,这里指结合计算机体系结构提高性能,纯减少算法复杂度的工作并没有包括在内。AMG解法器非常多,最近开发活跃的如下表:
| AMG解法器 | 开发者 | 说明 | 备注 |
|---|---|---|---|
| BoomerAMG | LLNL(HYPRE) | 实用比较广泛的经典AMG算法解法器 | 开源 |
| Pyamg | Luke Olson | 基于Python的AMG解法器 | 开源 |
| RAPtor | Bienz Amanda | 结点感知通信的AMG解法器 | 开源 |
| AMGCL | Demidov, Denis | 基于C++的AMG解法器 | 开源 |
| JXPAMG | 九所和湘潭大学 | 特征驱动的AMG解法器 | 开源 |
| FASP | 中科院数学与系统科学研究院 | 针对油藏模拟等应用领域开发 | 开源 |
| FASP++ | 中科院数学与系统科学研究院 | FASP的C++版本 | 开源 |
| AMGX | NVIDIA | 基于NVIDIA的GPU的AMG解法器 | 开源 |
| Saena | Majid Rasouli | 作者博士期间开发的AMG解法器 | 开源 |
| MueLu | Trilinos | Trilinos中的AMG解法器 | 开源 |
| GAMG | PETSc | PETSc中的AMG解法器 | 开源 |
| YHAMG | 国防科技大学 | 并行代数多重网格算法库 | 开源 |
| SAMG | Hans-Joachim Plum | 高效的AMG解法器 | 闭源 |
| AGMG | Yvan Notay | 光滑聚集的AMG | 闭源 |
解法器列表更新于:2023-10-04
随着超级计算机规模和实际应用需要的并行规模都在不断增加,AMG解法器性能问题分析和性能优化也成为了一个热门研究方向,总得来说大部分研究工作围绕HYPRE提出的问题开展(HYPRE的文章都可以在相关主页下载得到Publications · HYPRE),下面以年份列出文章列表(总共42篇文章):
2005
- R.D. Falgout, J.E. Jones and U.M. Yang, Pursuing Scalability for hypre’s Conceptual Interfaces, ACM Trans. Math. Softw., 31 (2005), pp. 326-350. UCRL-JRNL-205407.
- 介绍HYPRE中BoomerAMG的基础数据结构(ParCSR)和基于CommPkg的通信策略
2006
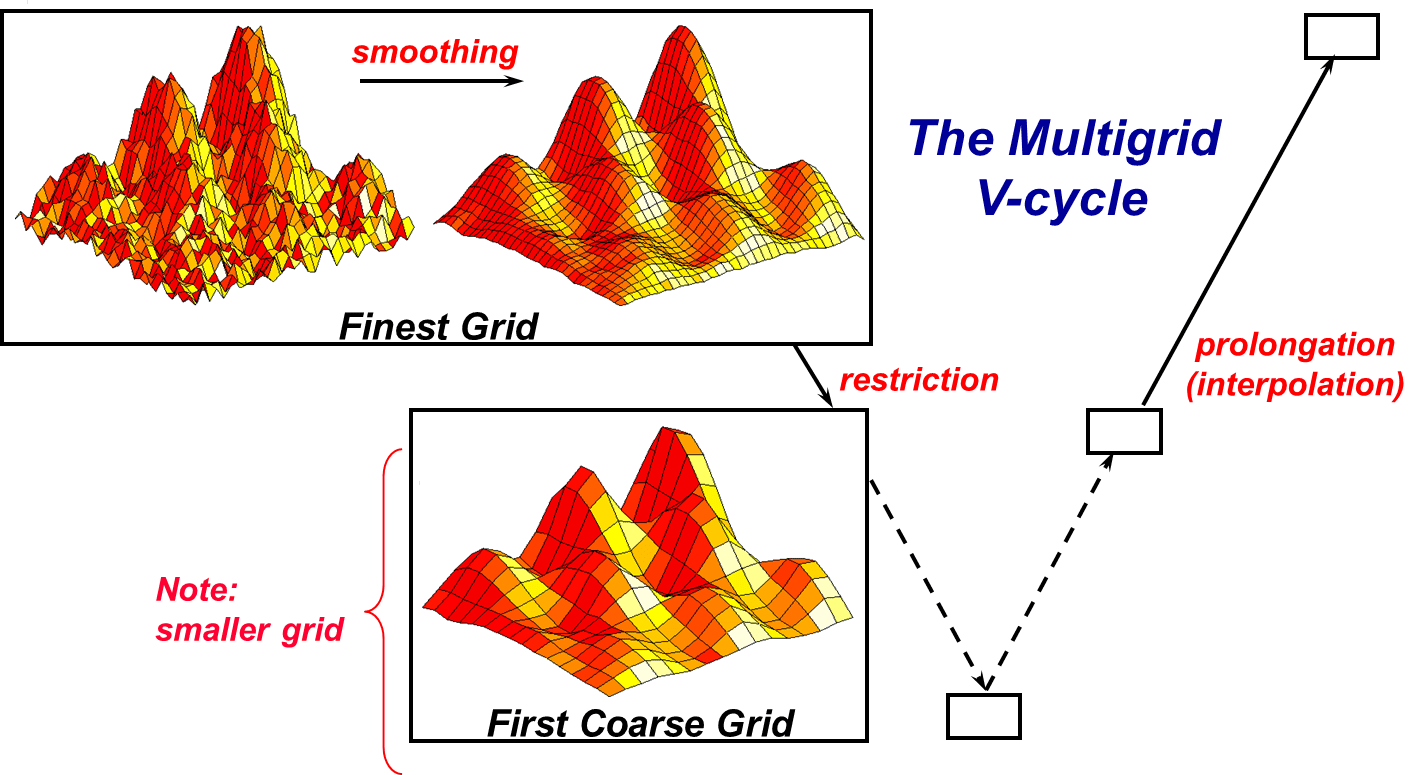
- R.D. Falgout, An Introduction to Algebraic Multigrid, Computing in Science and Engineering, Special Issue on Multigrid Computing, 8 (2006), pp. 24-33. UCRL-JRNL-220851.
- 非常简短的介绍AMG基本算法的文章
- A.H. Baker, R.D. Falgout, and U.M. Yang, An Assumed Partition Algorithm for Determining Processor Inter-Communication, Parallel Computing, 32 (2006), pp. 394-414. UCRL-JRNL-215757.
- 通常AMG中通信由通信包管理,决定进程的接收对象使用的是MPI_Allgatherv操作,作者提出一种假设数据划分的算法,来减少其中的聚合通信操作。
2007
- 徐小文, 莫则尧. 并行代数多重网格算法可扩展性能分析[J]. 计算物理, 2007, 24(4): 387-394.
- 网格算子的平均模式大小和迭代过程的算法效率分别制约了 AMG算法启动阶段和迭代求解阶段并行性能的发挥
2009
- 徐小文, 莫则尧, 曹小林. HYPRE 中多重网格解法器的并行可扩展性能分析[J]. 软件学报, 2009, 20(zk): 8-14.
- 比较了SMG和BoomerAMG,还有几种不同的粗化策略
2010
- Emans M, van der Meer A. Mixed-precision AMG as linear equation solver for definite systems[J]. Procedia Computer Science, 2010, 1(1): 175-183.
- (混合精度)将PCG中8-byte的AMG变为4-byte,能取得20%的加速效果
2011
- A.H. Baker, M. Schulz and U. M. Yang, On the Performance of an Algebraic Multigrid Solver on Multicore Clusters, in VECPAR 2010, J.M.L.M. Palma et al., eds., vol. 6449 of Lecture Notes in Computer Science, Springer-Verlag (2011), pp. 102-115. http://vecpar.fe.up.pt/2010/papers/24.php. LLNL-CONF-429864.
- 在Heria和Blue Gene/L两个超算平台测试BoomerAMG性能,发现两者弱可扩展性能差距大,由此拉开一系列性能分析和优化工作的序幕。文中提到了使用MPI+OpenMP的混合并行方式优化性能,并比较了不同绑定策略的性能,并提出了改进方案。
- H. Gahvari, A.H. Baker, M. Schulz, U.M. Yang, K. Jordan, and W. Gropp, Modeling the Performance of an Algebraic Multigrid Cycle on HPC Platforms, in Proc. of the 25th International Conference on Supercomputing (ICS 2011), Tucson, AZ, 2011, pp. 172-181. LLNL-CONF-465291.
- 针对3中出现的问题,从矩阵稀疏模式和AMG算法网格层级分析原因(使用性能分析工具TAU),发现粗网格层矩阵稠密导致,并以此提出AMG的Solve阶段性能模型
- 参考文献 [8] H. Gahvari and W. Gropp. An Introductory Exascale Feasibility Study for FFTs and Multigrid. In 24th IEEE International Parallel and Distributed Processing Symposium, Atlanta, GA, April 2010. 可以看一下
- A.H. Baker, T. Gamblin, M. Schulz, and U.M. Yang, Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures, in 25th IEEE International Symposium on Parallel and Distributed Processing, IPDPS 2011, Anchorage, AK, USA, 2011 - Conference Proceedings, IEEE (2011), pp. 275-286. LLNL-CONF-458074.
- 从通信角度详细分析粗网格层矩阵稠密会导致的网络竞争问题(V. PERFORMANCE RESULTS中),介绍是什么竞争:the code creates a high aggregated messaging rate across each node leading to a high pressure on the Infiniband network card, which further increases with growing node count. 高的聚合消息传递率给网卡造成巨大压力。
- 并以此提出混合并行策略优化,分析其优缺点。
- Förster M, Kraus J. Scalable parallel AMG on ccNUMA machines with OpenMP[J]. Computer Science-Research and Development, 2011, 26(3-4): 221-228.
- 针对CCNUMA优化多线程架构,相比于纯MPI达到线性加速比。想解决多CPU体系结构下多线程问题可以参考,但对当前实用性好像不大。
2012
- Neic A, Liebmann M, Haase G, et al. Algebraic multigrid solver on clusters of CPUs and GPUs[J]. Lecture notes in computer science, 2010: 389-398.
- 介绍PCG中CG部分代码在CPU和GPU上的性能
- A.H. Baker, R.D. Falgout, Tz.V. Kolev, and U.M. Yang, Scaling hypre’s Multigrid Solvers to 100,000 Cores, in High Performance Scientific Computing: Algorithms and Applications, M. Berry et al., eds., Springer (2012). LLNL-JRNL-479591.
- 介绍整个HYPRE为了达成10万核成功运行这一成就,采取的策略和AMG解法器优化,一篇总结过去HYPRE所有工作的文章
- A.H. Baker, R.D. Falgout, T. Gamblin, Tz.V. Kolev, M. Schulz, and U.M. Yang, Scaling Algebraic Multigrid Solvers: On the Road to Exascale, in Competence in High Performance Computing 2010, C. Bischoff et al., eds., Springer-Verlag (2012). Proc. of Competence in High Performance Computing, CiHPC 2010, Schwetzingen Germany. LLNL-PROC-463941.
- 对于上一篇文献中AMG解法器工作的总结,包括性能优化策略和不同的光滑算法
- H. Gahvari, W. Gropp, K. E. Jordan, M. Schulz, and U. M. Yang, Modeling the Performance of an Algebraic Multigrid Cycle Using Hybrid MPI/OpenMP, Proceedings of the 41st International Conference on Parallel Processing, Pittsburgh, PA, Sept 10-13, 2012. LLNL-CONF-533431.
- 将提出的AMG Solve阶段的模型推广到混合并行策略中,并加入更多的惩罚项
- H. Gahvari, W. Gropp, K. E. Jordan, M. Schulz, and U. M. Yang, Performance Modeling of Algebraic Multigrid on Blue Gene/Q: Lessons Learned, 3rd International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computing Systems (PMBS12), Supercomputing 12, Salt Lake City, Utah, Nov 11, 2012. LLNL-CONF-580692.
- AMG在Blue Gene/L上的弱可扩展性非常好,但结点内核数更多的新机器机器Blue Gene/Q(从2/4->16,每个核能同时运行4个硬件线程性能)上,发现可扩展性变差,作者基于此将自己提出的混合并行模型与新超算进行适配,提出了对于新超算上AMG面临的问题,也指出目前新超算上存在的不足。
- Sundar H, Biros G, Burstedde C, et al. Parallel geometric-algebraic multigrid on unstructured forests of octrees[C]//SC’12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE, 2012: 1-11.
- Our method is designed for meshes that are built from an unstructured hexahedral macro mesh, in which each macro element is adaptively refined as an octree. This forest-of-octrees approach enables us to generate meshes for complex geometries with arbitrary levels of local refinement. We use geometric multigrid (GMG) for each of the octrees and algebraic multigrid (AMG) as the coarse grid solver.
- 看摘要有以前讲的 AMREX 有点像
- Feng C, Shu S, Yue X. An improvement to the OpenMP version of BoomerAMG[C]//High Performance Computing: 8th CCF Conference, HPC 2012, Zhangjiajie, China, October 29-31, 2012, Revised Selected Papers. Springer Berlin Heidelberg, 2013: 1-11.
- 针对一系列带状矩阵的求解,设计对OpenMP友好的粗化和插值算法
- Kandalla K, Yang U, Keasler J, et al. Designing non-blocking allreduce with collective offload on InfiniBand clusters: A case study with conjugate gradient solvers[C]//2012 IEEE 26th International Parallel and Distributed Processing Symposium. IEEE, 2012: 1156-1167.
- 使用MPI-3中非阻塞通信方式优化HYPRE中CG实现的Allreduce
2013
- H. Gahvari, W. Gropp, K. E. Jordan, M. Schulz, and U. M. Yang, Systematic Reduction of Data Movement in Algebraic Multigrid Solvers, Proceedings of the 2013 IEEE 27th International Symposium on Parallel and Distributed Processing Workshops and PhD Forum (IPDPSW 2013). LLNL-CONF-587832.
- 基于前面建立的Solve阶段的模型,为了减少算法的通信量,动态且开销低地重新划分数据。
- Li J, Tan G, Chen M, et al. SMAT: An input adaptive auto-tuner for sparse matrix-vector multiplication[C]//Proceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation. 2013: 117-126.
- 基于AMG每层稀疏矩阵特点,自适应选取每层矩阵最优的SpMV格式
2014
- Bienz A, Olson L. Reducing Network Contention Associated with Parallel Algebraic Multigrid[J].
- SC14年学生竞赛投稿论文,只有两页纸,简洁地介绍了AMG中存在的问题,以及可以采取的性能优化方法。
- Sumiyoshi Y, Fujii A, Nukada A, et al. Mixed-precision AMG method for many core accelerators[C]//Proceedings of the 21st European MPI Users’ Group Meeting. 2014: 127-132.
- (混合精度)比较了5个不同机器平台(含有同构)的混合精度AMG性能,在不同问题上能取得1.2X-1.6X的加速,而且这些加速效果来源于最细层的SpMV操作。
- Richter C, Schöps S, Clemens M. GPU acceleration of algebraic multigrid preconditioners for discrete elliptic field problems[J]. IEEE transactions on magnetics, 2014, 50(2): 461-464.
- (混合精度)混合精度版本的时间开销是 FP64 版本的 84%。
2015
- 赵莲, 赵永华, 迟学斌. 基于计算与通信重叠的稀疏矩阵-向量乘积及其在 AMG 中的应用[J]. 数值计算与计算机应用, 2015, 36(3): 197.
- 建立新的数据结构,提出一类具有最小通信量以及隐藏通信的新SpMV,并实现了基于K-循环迭代的求解阶段并行算法。
- J. Park, M. Smelyanskiy, U.M. Yang, D. Mudigere, and P. Dubey, High-Performance Algebraic Multigrid Solver Optimized for Multi-Core Based Distributed Parallel Systems, Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis 2015 (SC15).
- 非常经典的AMG性能优化文章,发表在了SC15,针对单结点多核和多结点两个角度,在代码实现上分析存在的种种问题并进行优化,使得HYPRE在多节点的性能比基于GPU的AMGX更快。
- Gahvari H, Gropp W, Jordan K E, et al. Algebraic multigrid on a dragonfly network: First experiences on a Cray XC30[C]//High Performance Computing Systems. Performance Modeling, Benchmarking, and Simulation: 5th International Workshop, PMBS 2014, New Orleans, LA, USA, November 16, 2014. Revised Selected Papers 5. Springer International Publishing, 2015: 3-23.
- 在新型蜻蜓 (dragonfly) 超算网络拓扑上测试AMG的性能,并以此改进Solve阶段的性能模型,发现蜻蜓网络上,网络竞争消失,但不同于以前拓扑的结点分配策略,蜻蜓网络让结点分配的更散乱(参考Dragonfly拓扑简介 ),也使得网络通信的开销增大。
2016
- Druinsky A, Ghysels P, Li X S, et al. Comparative performance analysis of coarse solvers for algebraic multigrid on multicore and manycore architectures[C]//Parallel Processing and Applied Mathematics: 11th International Conference, PPAM 2015, Krakow, Poland, September 6-9, 2015. Revised Selected Papers, Part I 11. Springer International Publishing, 2016: 116-127.
- li xiaoye(SuperLU负责人)是其中作者之一,针对AMG两网格中最粗层系统的求解,对PCG和HSS方法分别进行优化,并比较两者性能,发现HSS性能较优。
- A. Bienz, R.D. Falgout, W. Gropp, L.N. Olson, and J.B. Schroder, Reducing Parallel Communication in Algebraic Multigrid Through Sparsification, SIAM J. Sci. Comput., 38 (2016), pp. S332-S357. LLNL-JRNL-673388. Supplimentary material.
- Bienz基于她在SC14上提出的保持粗网格层矩阵稀疏化的想法,根据收敛性加上了自适应保持稀疏化的策略。
2018
- Bienz A. Reducing communication in sparse solvers[J]. 2018.
- Bienz的博士毕业论文,包含三个工作:建立稀疏点对点的通信模型,AMG粗网格矩阵自适应稀疏性和结点感知通信策略,最后这些策略都应用到AMG中。
- Rasouli M, Zala V, Kirby R M, et al. Improving Performance and Scalability of Algebraic Multigrid through a Specialized MATVEC[C]//2018 IEEE High Performance extreme Computing Conference (HPEC). IEEE, 2018: 1-7.
- 采取调整行优先和列优先顺序、计算与通信重叠、通信负载均衡等策略优化AMG中的SpMV组件
2019
- Rasouli M, Zala V, Kirby R M, et al. Scalable Lazy-update Multigrid Preconditioners[C]//2019 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 2019: 1-7.
- 挺有意思的一篇文章,使用粗层懒加载方式(不改变结构,延迟值得更新),以此解决粗层矩阵稠密导致得网络竞争问题。
- Zhang C, Li R, Jiang H. Optimization of GPU Kernels for Sparse Matrix Computations in Hypre[J]. 2019.
- 又是SC(19)的两页纸文章,二作是Ruipeng Li,他们在GPU上优化了HYPRE的基础内核:SpMV、SpTrSv和SpGEMM。
- Bienz A, Gropp W D, Olson L N. Node aware sparse matrix–vector multiplication[J]. Journal of Parallel and Distributed Computing, 2019, 130: 166-178.
- 对于SpMV中的点对点通信,提出一种结点聚合的策略,减少网络中需要通信的进程数
- 徐小文. 并行代数多重网格算法:大规模计算应用现状与挑战[J]. 数值计算与计算机应用, 2019, 40(4):243-260.
- 比较全面的介绍目前AMG规模计算需要面对的问题
- Clark K. Effective use of mixed precision for hpc[C]//Smoky Mountain Conference. 2019.
- (混合精度的一个报告)网上有PPT和视频
2020
- Bienz A, Gropp W D, Olson L N. Reducing communication in algebraic multigrid with multi-step node aware communication[J]. The International Journal of High Performance Computing Applications, 2020, 34(5): 547-561.
- 为了解决网络竞争,在上一篇文章基础上,提出两种多步结点感知通信策略,并提出通信模型自适应选择策略,最终应用在AMG中
- Sahasrabudhe D, Berzins M. Improving performance of the hypre iterative solver for Uintah combustion codes on manycore architectures using MPI endpoints and kernel consolidation[C]//Computational Science–ICCS 2020: 20th International Conference, Amsterdam, The Netherlands, June 3–5, 2020, Proceedings, Part I 20. Springer International Publishing, 2020: 175-190.
- 这篇讲Uintah,类似于JASMIN和JUMIN的前处理框架,怎么合理利用多线程调用HYPRE,MPI Endpoint作用应该是 thread as rank.文章条理比较清晰,提出的问题和解决问题的思路比较明确。
- Q.M. Bui, D. Osei-Kuffuor, N. Castelletto, and J.A. White, A Scalable Multigrid Reduction Framework for Multiphase Poromechanics of Heterogeneous Media, SIAM J. Sci. Comput., 42 (2020), pp. B379-B396. LLNL-JRNL-772001.
- R. Li and C. Zhang, Efficient Parallel Implementations of Sparse Triangular Solves for GPU Architectures, Proceedings of the 2020 SIAM Conference on Parallel Processing for Scientific Computing, pp. 106-117. LLNL-PROC-799059.
- 应该是以前的工作重新整理一下,内容为在GPU上高效的并行稀疏三角解实现
- R. Li, B. Sjogreen, and U.M. Yang, A New Class of AMG Interpolation Methods Based on Matrix-Matrix Multiplications, SIAM J. Sci. Comput., online (2021). LLNL-JRNL-812088.
- 为了提升AMG中构造插值算子函数的性能,提出了一种基于矩阵矩阵乘的插值算子构造方法。
- R.D. Falgout, R. Li, B. Sjogreen, U.M. Yang, and L. Wang, Porting hypre to Heterogeneous Computer Architectures: Strategies and Experiences, Parallel Computing, 108 (2021). LLNL-JRNL-816235.
- 整理了整个HYPRE适配GPU所采取的策略,原则上尽量使用CUDA接口,其它的接口尽量基于warp重新编写代码
2021
- Holmes D J, Skjellum A, Jaeger J, et al. Partitioned collective communication[C]//2021 Workshop on Exascale MPI (ExaMPI). IEEE, 2021: 9-17.
- 有Bienz在里面就发现这篇文章,讲的是以后MPI-4.0会有通信划分,不只是集合通信,包括与Bienz工作类似的点对点通信
- Pichahi S M R. Improving the Performance and Scalability of Algebraic Multigrid[D]. The University of Utah, 2021.
- 另一篇与AMG性能相关的博士毕业论文,导师:Hari Sundar
- 博士毕业做了三个工作,SpMV的性能优化、SpGeMM的性能优化和粗层通信优化(Lazy update)工作。
- 衍生论文:
- A Compressed, Divide and Conquer Algorithm for Scalable Distributed Matrix-Matrix Multiplication
- Improving Performance and Scalability of Algebraic Multigrid through a Specialized MATVEC
- Scalable Lazy-update Multigrid Preconditioners
- Rasouli M, Kirby R M, Sundar H. A compressed, divide and conquer algorithm for scalable distributed matrix-matrix multiplication[C]//The International Conference on High Performance Computing in Asia-Pacific Region. 2021: 110-119.
- 不同于经典ParCSR划分方式,作者自己建立一套划分方式优化AMG中的SpGEMM
- Abdelfattah A, Anzt H, Boman E G, et al. A survey of numerical linear algebra methods utilizing mixed-precision arithmetic[J]. The International Journal of High Performance Computing Applications, 2021, 35(4): 344-369.
- (混合精度)关于线性代数方法使用混合精度的综述文章,有一章节介绍AMG中的混合精度方法
- Fox A, Kolasinski A. Error analysis of inline zfp compression for multigrid methods[C]//2019 Copper Mountain Conference for Multigrid Methods. 2019.
- 这篇文章挺有意思的,使用zfp压缩位数发现能较好的减少时间开销和内存
- Buttari A, Huber M, Leleux P, et al. Block low‐rank single precision coarse grid solvers for extreme scale multigrid methods[J]. Numerical Linear Algebra with Applications, 2022, 29(1): e2407.
- (混合精度)低精度的粗网格求解器
2022
- Boukhris S, Napov A, Notay Y. Algebraic multigrid using a stencil-CSR hybrid format on GPUs[J]. 2022.
- AGMG开发者Notay Y为通讯作者,利用网格的Stencil信息,设计一种对GPU友好且存储量少的CSR格式,用于聚集型的AMG,相比于HYPRE和AMGX都取得了加速效果。
2023
-
Thune A, Reinemo S A, Skeie T, et al. Detailed modeling of heterogeneous and contention-constrained point-to-point MPI communication[J]. IEEE Transactions on Parallel and Distributed Systems, 2023.
- 与AMG无关,但改进了以前的点对点通信模型。
-
Fan M, Tian X, He Y, et al. AmgR: Algebraic Multigrid Accelerated on ReRAM[J]. DAC’23
- 针对光滑聚集的AMG算法,基于存内计算设计的专用硬件。
-
Yang X, Li S, Yuan F, et al. Optimizing Multi-grid Computation and Parallelization on Multi-cores[C]//Proceedings of the ACM International Conference on Supercomputing. ACM, 2023.
- 针对混合对称GS设计一种异步通信策略
-
Li C, Graillat S, Quan Z, et al. XHYPRE: a reliable parallel numerical algorithm library for solving large-scale sparse linear equations[J]. CCF Transactions on High Performance Computing, 2023: 1-19.
- 为解决HYPRE中精度问题导致不收敛,提出的混合精度HYPRE
2024
- Wang Y, Chang F, Wei B, et al. Optimization of Sparse Matrix Computation for Algebraic Multigrid on GPUs[J]. ACM Transactions on Architecture and Code Optimization, 2024.
- 提出了一个新的SpGEMM
- 基于GPU丰富的实现,使用ML选择AMG每层的SpGEMM和SpMV实现